








Introduction
Data is worthless unless you can process it, analyze it, and find hidden insights. Data pipelines help you do that. They enable the speedy data flow from a source like a database or a spreadsheet to a final destination like a data warehouse.
What is a data pipeline?
A data pipeline is a set of tools and processes that is used to automate the movement as well as the transformation of data from a source system to a target repository. With big data pipelines, you can extract, transform, and load (ETL) massive amounts of information.
This article will outline the top 8 data pipeline tools for 2022.
What are the top 8 data pipeline tools for 2022?
Integrate.io
Integrate.io is a cloud-based data pipeline tool that requires no code. It moves data from one source to another via the extract, transform, load (ETL) process. However, you can also transfer data to a final destination via extract, load, and transform (ELT).

Source: ec.europa.eu
AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. If parts of a data pipeline are already on AWS, using Glue becomes straightforward. You can create an ETL job easily because you already understand the AWS Management Console.
Since AWS Glue is integrated across most AWS services, the onboarding process is straightforward. AWS Glue natively supports data stored in Amazon S3 buckets, Amazon Redshift, Amazon Aurora, and other Amazon RDS engines.
Fivetran
Fivetran only moves data through pipelines via ELT. ETL has no option, which might limit businesses from searching for the best data pipeline tools. Still, world-class security, standardized schemas, and event data flow for unstructured data make this a superb choice.
Stitch
Stitch has a range of features, such as secure data transfers with no firewall infiltrations, integration with various data sources and destinations, and real-time evaluations of user experiences. The UI is simple, making it an outstanding choice for smaller teams.
dbt – data build tool
dbt allows anyone with SQL skills to own the entire data pipeline, from writing data transformation code to deployment and documentation. dbt enables you to perform complex and powerful transformations on your data with all the central data warehouses, such as Redshift, Snowflake, and BigQuery, using software engineering best practices. dbt natively supports version control, Git integration, and logging.
Apache Spark
Apache Spark is an open-source data pipeline tool. Some of its features include a thriving community on Stack Overflow, support for graphics processing, and the opportunity to create no-code pipelines for quick-and-easy data insights.
Hevo Data
A data pipeline as a service that requires no coding skills. it allows you to load data from other sources into your own data warehouse such as Snowflake, Redshift, BigQuery, etc. in real-time.
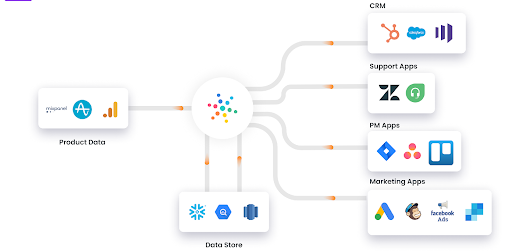
Source: hevodata.com
Dataform
Dataform is an ELT data pipeline tool that lets you manage all data operations in Panoply, Redshift, BigQuery, and Snowflake, following ELT best practices using SQL. Dataform has a free, open-source software package, SQLX, to build data transformation pipelines from the command line.
Every SQLX model is a simple SELECT statement. You can easily create dependencies between tables with the ref function. Tell Dataform what kind of relationship you want to create, and SQLX manages all the create, insert, and drop boilerplate code for you.